
I’m sure you spend a lot of time thinking about how to write better software just like I do. And if you’ve dipped your toes into the waters of unit testing best practices, you will have undoubtedly asked this question at some point: how simple is too simple to test?
(As an Amazon Associate I earn from qualifying purchases.)
Well, today I found an error in one of my projects that suggests that there might not be a lower bound. Check this out:
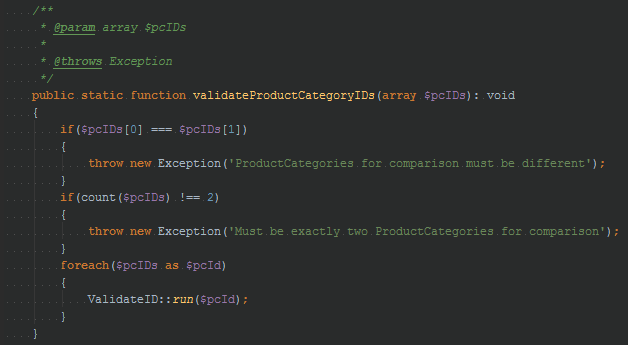
This method does some checks on the contents of $pcIDs and throws an exception if something goes wrong. Simple, right? Of course. It’s only 15 lines of code, including the signature and parentheses.
Would you believe this code contains an error? Let me give you a hint:
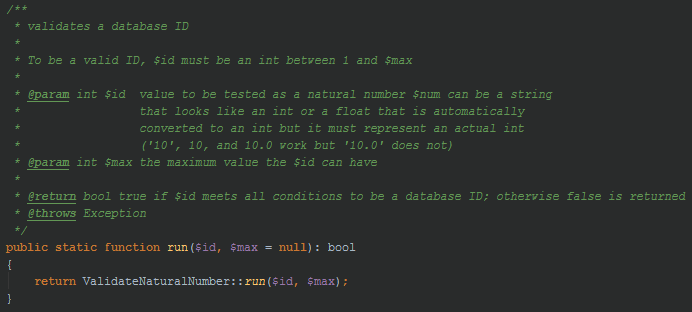
Do you see the problem (take your time, I’ll wait).
waiting…
waiting…
waiting…
waiting…
waiting…
Figure it out yet? Need a more obvious hint?
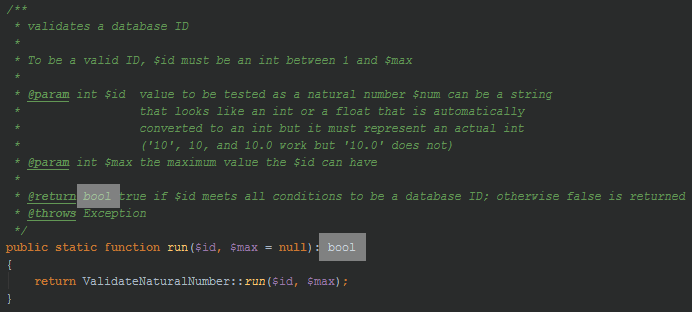
What happened
See what happened there? We want $pcID[0] and $pcID[1] to be the only values in the input array. They should be integers > 0 and not equal to each other. At first glance the method appears to work correctly. But upon closer inspection you probably realized that ValidateID::run() returns a bool but this code doesn’t check the return value. Instead it assumes that ValidateID::run() will throw an exception if the value is invalid.
So, validateProductCategoryIDs(array(‘cat’, ‘dog’)); will not throw an exception, which is not the behavior we want.
Unit testing best practices
So, how simple is too simple to test? I’m starting to come around to the point of view that almost nothing is too simple to test.
There’s a quote I like but I can’t remember who wrote/said it:
Write tests for any behavior you care about.
Indeed. This fits in nicely with a lecture on Computer Bugs in Hospitals (great talk–by the way). The lecturers argue that doctors and nurses enter incorrect data into computer systems all the time. And some of those errors kill patients. But here’s the part that’s important for us–they don’t know they made a mistake. A nurse entering drug doses into an infusion pump with a numeric keypad makes a mistake that they do not catch about 4% of the time! Doesn’t that seem like a high error rate?
So, if nurses are messing up simple number entry tasks without noticing, how often are programmers inserting silly errors into their code without noticing? I think the answer is probably a lot.
The code I’m showing you in this post was written with care. The author wrote a comprehensive manual testing plan for it but no unit tests. The code was reviewed by the author using our code review checklist. And then I also reviewed the code using our code review checklist and executed the manual testing plan. And, after all of that QA, we still missed this pretty obvious error.
So how did we catch this error today?
My colleague wrote unit/integration tests for a method that calls the validateProductCategoryIDs() method. He actually didn’t notice the problem but when I was doing a code review on his new tests, I noticed that array(‘cat’, ‘dog’) types of inputs were not resulting in exceptions and I thought that was suspicious.
To summarize, we needed automated testing combined with code reviews to catch this error. Even though this was a simple error, neither manual testing, unit testing, nor code reviews alone were enough to bring this error to our attention. We only discovered this error by combining several kinds of quality assurance activities.
By the way, this is exactly what Steve McConnell recommends in Code Complete (paid link)–multiple kinds of QA because each kind catches different kinds of errors.
A couple of thoughts about clean coding practices
We’ll never know exactly what happened in the mind of the programmer who originally wrote this code but I can tell you with confidence that this was not an intentional error.
If you do a little root cause analysis you’ll notice that we have two validation methods in the code I’ve shown you. One returns void or throws an exception and the other returns bool. And that’s confusing as hell.
Don’t use a confusingly similar naming system for methods that return incompatible types
Having validateXXX methods that return incompatible types is probably a code smell. And I’d be willing to bet you that it contributed to us not catching the error during code review.
We could probably reduce the potential for the same kind of errors in the future by changing some of the names of the validateXXX methods to “verifyXXX.” That would make it clear that validate methods return bool and verify methods throw exceptions if they encounter data they don’t like. Our IDE has strong refactoring support so we can make that kind of change quickly and safely.
Catch this kind of potential error with a static analysis inspection
My preferred solution is to use a static analysis inspection that’s integrated into our IDE to help us find all instances of this class of problems while we are coding. I’m not sure how easy it would be to turn on that kind of inspection in our project but I’m sure you can see the appeal.
Takeaways
Even the best programmers make mistakes. You might be able to catch some of them with careful code reviews and good clean code practices. But you need to combine multiple QA methods if you want really low defect rates. Your unit testing best practices should include testing any behavior you care about, even for code that might appear to be too simple to contain an error.
Agree or disagree? I’d love to hear your thoughts in the comments.
Nice article, thanks.
Though, the first thing I noticed in the code is that the function use elements of the input array to do some checks, and only then check the size of that array.
What happens with validateProductCategoryIDs(array(‘12’)); or validateProductCategoryIDs(array()); ?
Nice catch.
I cross-posted this article on dev.to and someone else asked the same thing. An array containing a single element will cause the first exception to be raised and a notice will be emitted when the code tries to access the non-existent element (if you have error reporting turned up high enough).
In the case of an empty array, two notices are emitted (one for each non-existent array access but null === null so the first “if” evaluates as true and the array size exception is raised.
However, both of your test inputs result in the the same exception class being raised. So, in this case there is zero behaviour difference in our application. But the code would be more correct if the array size check came before the value comparison (I changed this code in production to match when this was brought to my attention).
Cheers.